POD-DL-ROM: Enhancing deep learning-based reduced order models for nonlinear parametrized PDEs by proper orthogonal decomposition
Abstract
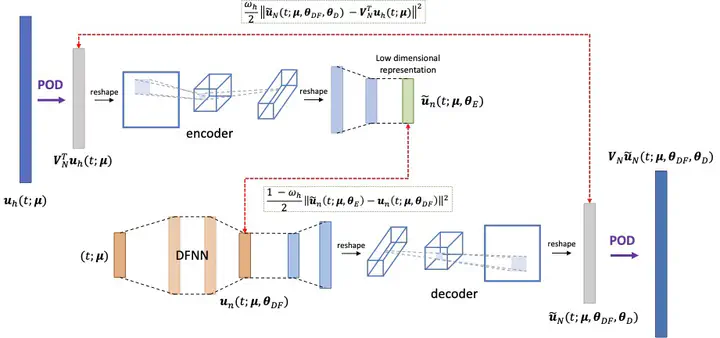
Deep learning-based reduced order models (DL-ROMs) have been recently proposed to overcome common limitations shared by conventional reduced order models (ROMs) – built, e.g., through proper orthogonal decomposition (POD) – when applied to nonlinear time-dependent parametrized partial differential equations (PDEs). These might be related to (i) the need to deal with projections onto high dimensional linear approximating trial manifolds, (ii) expensive hyper-reduction strategies, or (iii) the intrinsic difficulty to handle physical complexity with a linear superimposition of modes. All these aspects are avoided when employing DL-ROMs, which learn in a non-intrusive way both the nonlinear trial manifold and the reduced dynamics, by relying on deep (e.g., feedforward, convolutional, autoencoder) neural networks. Although extremely efficient at testing time, when evaluating the PDE solution for any new testing-parameter instance, DL-ROMs require an expensive training stage, because of the extremely large number of network parameters to be estimated. In this paper we propose a possible way to avoid an expensive training stage of DL-ROMs, by (i) performing a prior dimensionality reduction through POD, and (ii) relying on a multi-fidelity pretraining stage, where different physical models can be efficiently combined. The proposed POD-DL-ROM is tested on several (both scalar and vector, linear and nonlinear) time-dependent parametrized PDEs (such as, e.g., linear advection–diffusion–reaction, nonlinear diffusion–reaction, nonlinear elastodynamics, and Navier–Stokes equations) to show the generality of this approach and its remarkable computational savings.
Stefania Fresca
Assistant Professor
My research interests are scientific machine learning, reduced order modeling and AI.